
생활코딩 - HTML을 공부하며 정리한 내용입니다.
개요
우리가 흔히 사용하는 네이버, 구글과 같은 검색엔진에서는 사용자가 원하는 정보에 대한 링크를 수집해서 보여준다. 이것이 가능한 것은 검색엔진 회사들마다 모든 웹사이트에 보내는 크롤러(crawler)라는 로봇 덕분이다. 크롤러는 거의 대부분의 페이지들을 탐색하며 해당 페이지에 대한 정보를 얻어낸다.
그런데 사람이야 눈으로 글을 읽거나 이미지를 보며 정보를 획득하지만, 로봇은 어떻게 정보를 획득하는걸까? 바로 로봇은 HTML구조와 그 안에 담긴 텍스트를 분석함으로써 정보를 획득하고 종합하여 사용자들에게 적합한 형태로 보여준다.
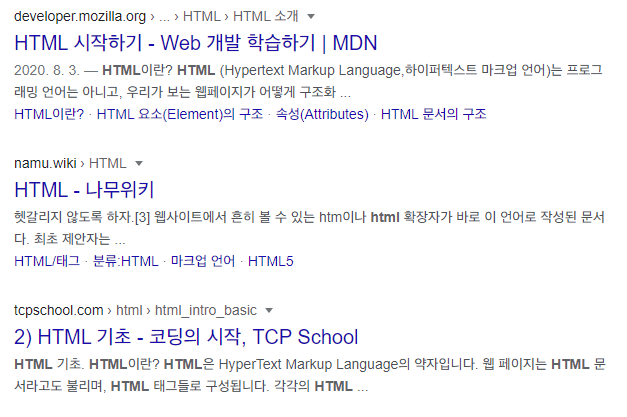
그래서 특정 키워드에 대해서 연관이 높은 내용을 담고 있을 수록, 그리고 HTML 구조가 로봇이 이해하기에 적합한 형태로 페이지를 구성하면 검색결과에서 상위에 노출될 가능성이 높아질 수 있다는 것을 유추할 수 있다. 이처럼 페이지가 검색 엔진에서 노출이 잘 되도록 하는 것을 검색 엔진 최적화(Search Engine Optimization; SEO)라고 부른다.
본 포스팅에서는 다음과 같은 내용을 다룬다.
- HTML 구조
- Meta Data(메타 데이터)
- 모바일 지원(viewport)
- 의미론적 태그(Semantic Tag)
- 검색엔진 최적화
- 링크 최적화
- 콘텐츠 최적화
- 이미지 사용 최적화
- robots.txt
하나씩 차근차근 알아보도록 하자.
HTML 구조
HTML의 구조는 크게 3부분으로 나뉜다.
html: HTML 문서 전체를 의미head: HTML 문서에 부가적으로 들어가는 정보들body: HTML 문서의 본문
코드로 표현하면 아래와 같이 표현할 수 있다.
<!DOCTYPE HTML>
<!-- 브라우저에 HTML 문서가 어떤 표준에 맞추어 작성되었는지 알려주는 역할을 한다. ex)XHTML1.0
HTML5에서는 DOCTYPE HTML로 통합되었다. -->
<html> <!-- HTML 문서 전체를 감싸는 역할을 한다. -->
<head> <!-- 본문을 꾸미거나, HTML에 대한 부가정보를 포함한다. -->
<title>웹 브라우저에서 표시될 제목</title>
<meta charset="utf-8"> <!-- 본문의 인코딩을 utf-8로 지정한다. -->
</head>
<body>
HTML 본문에 해당하는 내용이 들어간다.
</body>
</html>
Meta Data(메타 데이터)
Meta Data는 데이터에 대한 데이터이다. 다시 말하자면, 다른 데이터를 설명하기 위해서 사용되는 데이터이다.
HTML은 다양한 정보를 담은 정보인데, 해당 HTML 문서에 대해 부가적인 정보를 표현하기 위해 <meta>태그를 사용한다. HTML이라는 정보를 조금 더 가치 있는 정보로 만들기 위해서 사용한다고 이해할 수 있다.
<html>
<head>
<meta charset="utf-8">
<meta name="description" content="Hello HTML!">
<meta name="keywords" content="코딩, coding, 프로그래밍, html, css, js">
<meta name="author" content="joon">
<meta http-equiv="refresh" content="30">
</head>
<body>
안녕하세요. HTML에 대해서 정리한 문서입니다.
</body>
</html>
위에서 사용된 속성들에 대해서 하나씩 설명하자면 다음과 같다.
charset: HTML 문서의 인코딩 형식을 나타내는 속성. 해당 속성이 존재하지 않으면 브라우저가 마음대로 해석을 하기 때문에, 글자가 깨져서 보인다.name="description": 해당 문서에 대한 요약이다. 우리 눈에는 보이지 않지만, 검색엔진에서 검색했을 때 요약 정보로 표시될 수 있다.name="keywords": 해당 문서에 대한 키워드 목록이다. 마찬가지로 검색엔진 최적화에 사용될 수 있다.name="author": 해당 문서의 저자를 의미한다.http-equiv="refresh": 자주 사용하지는 않지만,content에 설정한 초를 주기로 새로고침이 실행된다.
모바일 지원(viewport)
name="viewport"를 사용하면 데스크탑용으로 작성한 페이지를 모바일 기기에서도 보기 적합한 사이즈로 조절해준다.
<meta name="viewport" content="width=device-width, initial-scale=1.0">
content 이후에 표시되는 내용들을 설명하자면 다음과 같다.
width=device-width: 모바일 기기에서 표시되는 페이지의 너비를 기기의 너비에 맞춰서 조절한다.initial-scale=1.0: 페이지 확대/축소의 정도를scale이라고 하는데, 이를 1.0(기본값)으로 설정한다.
의미론적 태그(Semantic Tag)
시맨틱 태그(Semantic tag)는 HTML 문서를 의미 단위로 구분하기 쉽게 사용하는 태그이다. HTML5부터 본격적으로 사용되기 시작했다. 기존에는 div 태그를 이용해 개발자가 임의대로 나눠서 HTML 구조를 한 번에 이해하기 어려웠는데, 시맨틱 태그는 이러한 한계를 극복하기 위해서 등장하였다.
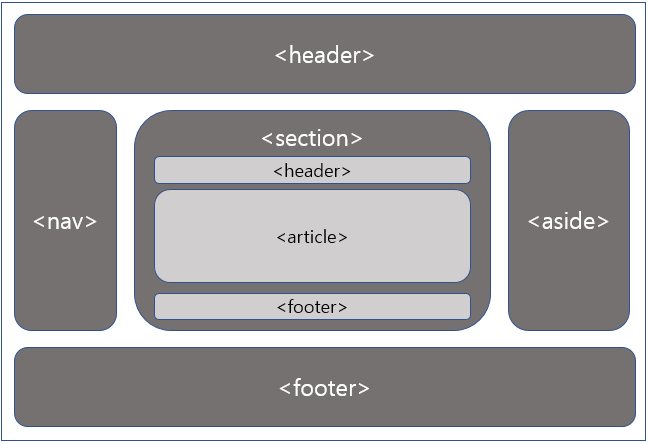
현대의 웹 페이지는 위와 같은 구조를 띄고 있다. 시맨틱 태그가 div 태그와 다른 기능을 수행하는 것은 아니고, HTML 구조를 한 눈에 알아보기 쉽게 사용하는 태그이다. 시맨틱 태그를 하나씩 살펴보면 다음과 같다.
header: 페이지의 상단에 보이는 영역이다. 주로 머리말이나 제목을 표현하기 위해 사용한다.nav: 네비게이션이라고 불리며, 같은 사이트 내의 링크나 다른 사이트로의 링크들을 모아놓은 태그이다.section: 본문의 의미를 가지고 있으며, 여러 article을 모아놓은 태그이다. 본문의 갯수에 따라 여러 section을 가질 수 있다.aside: 페이지 좌측 또는 우측에서 페이지 콘텐츠를 제외한 내용을 표시하는 태그이다. 주로 광고나 사이드 바가 위치한다.footer: 페이지 하단에 위치하는 태그이다. 주로 저작권, 연락처 정보와 같은 내용이 삽입된다.
이 외에도 다양한 시맨틱 태그가 사용되고 있는데, 크롬의 개발자 도구를 이용해서 다양한 웹 페이지를 둘러보면 시맨틱 태그가 어떻게 사용되는지 감이 올 것이다. 무엇보다 가장 좋은 방법은 직접 페이지를 제작해보는 것이다. 😊
검색엔진 최적화(SEO; Search Engine Optimization)
검색 엔진 최적화란 웹 페이지 검색 엔진이 자료를 수집하고 순위를 매기는 방식에 맞게 웹 페이지를 구성해서 검색 결과의 상위에 나올 수 있도록 하는 작업이다.
구글이나 네이버와 같은 회사에서 제공하는 검색 엔진은 사용자가 검색한 내용에 적합한 웹 사이트를 보여준다. 검색 엔진 회사들은 각각의 웹 페이지마다 페이지를 해석하고 분석하는 로봇을 보내는데, 정해진 기준에 맞추어 분류를 하고, 사용자가 검색했을 때 가장 적합한 콘텐츠를 보여준다.
링크 최적화
1. <title> 태그의 정보
- 책이나 신문과 비슷하게 가장 먼저 정보를 흡수할 수 있는 것은 제목이다. 마찬가지로 페이지에도 제목을 명확하게 표시해주어야 한다.
- 예를 들어,
HTML 강의라는 정보가 A페이지에는 웹 페이지의 제목인<title>태그에 있고, B페이지에는 본문의<li>태그에 포함되어 있다고 해보자. 이때, 검색엔진이 가장 먼저 결과를 보여주는 우선순위는<title>이라는 것이다.
.png)
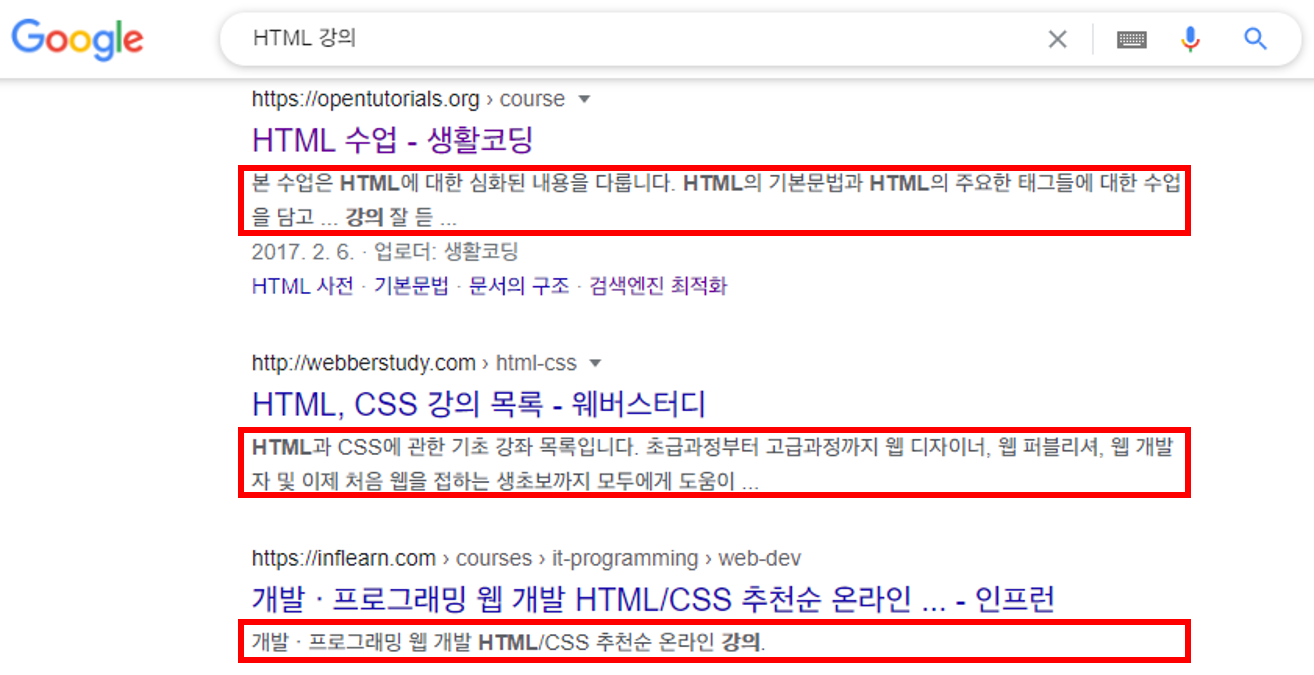
2. meta 태그의 description 속성
- 페이지에 부가정보 담을 수 있는
<meta>태그에description속성을 이용해서 페이지에 대한 요약 정보를 잘 나타낼 수록 상위 검색 결과로 노출된다. - 위의 사진처럼 구글에서 검색을 했을 때, 페이지 링크 밑에 간단하게 보여주는 정보이다. 따라서 사용자의 직관적인 이해를 돕기 위해서는 1~2줄이나 짧은 단락으로 구성하는 것이 좋다.
3. 페이지의 URL 구조
콘텐츠의 내용을 잘 보여주는 URL로 구성을 한다. Ex) 고양이가 좋아하는 간식에 대해 쓴 블로그 게시물에는
http://blog.naver.com/a3242dcm.html보다http://blog.naver.com/cats-like-these-foods.html과 같은 URL이 좋다.가급적이면 디렉토리가 단순한 URL을 구성한다. EX)
http://localhost:8080/blog/page/function/post/30.html처럼 깊은 하위 디렉토리를 사용하는 것이 아닌http://localhost:8080/post/30.html얕은 디렉토리를 사용한 URL을 사용한다.
4. 특정 문서에 도달하기 위한 한 가지 형태의 URL 제공
같은 내용의 페이지가 2개 있다고 하면, URL을
리디렉션(redirection)하여 1개의 페이지에서 접속할 수 있도록 설정한다.만약
redirection을 사용할 수 없다면,<link>태그에rel="canonical"속성을 사용함으로써 두 페이지 모두 같은 내용이라는 것을 암시해줄 수 있다.

EX) <link rel="canonical" href="http://localhost:8080/first.html"> 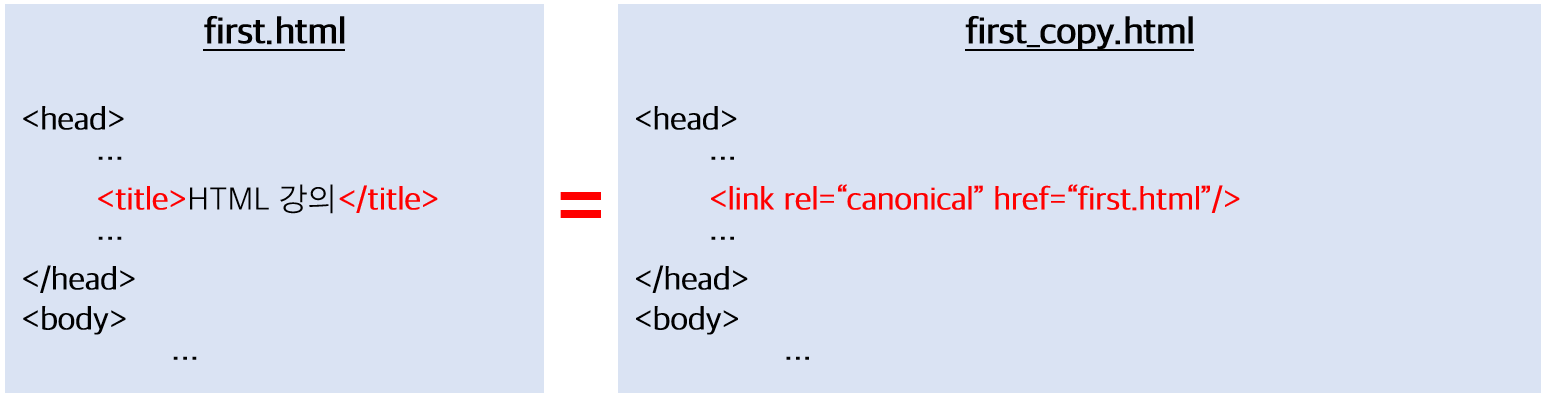
5. 사이트 내에서 이동하기 쉽게 만들기
- 크롤링을 하는 로봇들은 사이트 내의 페이지끼리 링크로 잘 연결되어있다면 정보를 쉽게 가져갈 수 있게 된다.
6. 홈페이지를 기반으로 한 이동 경로 계획
- 모든 사이트는 접속하면 가장 먼저 보이는 대문 페이지(홈페이지)가 존재한다. 주로
index.html이 홈페이지가 되는데, 이는 사용자가 가장 많이 방문하는 페이지이며, 탐색을 시작하는 위치이다. 따라서 사용자가 첫 페이지에서 더 구체적인 콘텐츠가 있는 페이지로 이동하는 방법에 대해서 생각해야 한다.
7. ‘사이트 이동 경로의 사용’으로 방문자에게 편리 제공하기

- 현재 접속한 페이지가 어느 위치인지 표시해주는 네비게이션을 이용한다.
8. 사용자가 URL의 일부를 제거하는 상황을 고려
- 사용자들 중 URL의 일부를 삭제해서 개발자가 의도하지 않은 페이지를 탐색하는 경우를 대비해야 한다.
- 예를 들어,
http://opentutorial.org/course/2039를http://opentutorial.org/admin으로 접속하면 일반 사용자들이 관리자 페이지로 접속할 수도 있게 된다. - 따라서 사용자가 임의의 페이지를 탐색할 수 없도록
404 Error를 표시해주거나, 상위 디렉토리http://opentutorial.org로 이동시키는 방법이 있다.
9. 자연스러운 계층 구조 만들기
- 사용자가 일반적인 내용에서 구체적인 내용으로 쉽게 이동할 수 있도록 사이트를 구성한다.
10. 이동 경로를 위해 텍스트 링크를 사용
- 보통은 링크를 연결하기 위해서
<a>태그를 사용하지만,javascript를 사용하면 콤보박스나 다른 태그 요소에서도 링크를 연결할 수 있다.<select onchange="location.href=this.value"> <option value="sign_up.html">회원가입</option> <option value="pw_find.html">비밀번호 찾기</option> </select>
콘텐츠 최적화
- 보다 나은 앵커 텍스트 작성
<a>태그를 이용해서 페이지를 연결할 때, 텍스트의 내용을 사용자와 검색 엔진 로봇이 이해하기 쉽도록 작성하는 것이 좋다는 것이다.<a href="http://naver.com">http://naver.com</a>처럼 텍스트를 링크로 작성하는 것이 아닌<a href="http://naver.com">네이버</a>로 작성한다.여기를 클릭,페이지,문서와 같은 텍스트는 사람이 봤을 때는 직관적으로 이해할 수 있어도 로봇은 이해하기 어렵고, 정보로서의 가치도 현저히 낮아지기 때문에 이러한 텍스트는지양해야 한다.
- 링크를 눈에 띄기 쉽게 포맷하기
- CSS를 활용해서 일반 텍스트와 링크의 앵커 텍스트를 쉽게 구분하게 한다. 이는 사용자가 링크를 놓치거나 실수로 클릭하는 경우를 방지하기 위함이다.
- 제목 태그를 활용해서 중요한 부분 강조하기
<h1>부터<h6>까지 제목을 강조하기 위한 태그를 적절히 사용해서 시각적으로 중요한 인식을 주고, 가독성을 높여주어 상세 콘텐츠를 이해하는 데 도움을 준다.
<h1>자기소개</h1>
<h2>이름</h2>
<span>홍길동</span>
<h2>소속</h2>
<span>지구별</span>
이미지 사용의 최적화
alt속성 사용
이미지가 깨졌을 때 대체해서 보여줄 텍스트를 설정하는
alt속성은 시각장애인 분들처럼 스크린뷰를 사용할 때에도 유용한 정보를 제공해줄 수 있다.<img src="logo.png" alt="로고 이미지입니다.">

- 이미지를 위한 디렉토리 설정
src속성으로 작성하는 이미지의 경로에는 이미지 파일만을 위한 디렉토리를 이용하는 것이 좋다.<img src="images/logo.png" alt="로고 이미지입니다.">
- 간결하고 설명적인 파일 이름 사용
- 임의로 지정한 파일 이름이 아닌 이미지에 대한 정보를 담고 있는 파일 이름을 작성한다.
- 예를 들어, 로고 이미지 파일은
123.png보다logo.png라고 저장하는 것이 훨씬 직관적이다.
- 이미지를 링크로 사용할 때,
alt속성 사용하기<a href="1.html"> <img src="images/logo.png" alt="로고를 클릭하면 홈페이지로 이동합니다."> </a>
robots.txt
robots.txt는 웹 페이지에 접근하는 크롤러 로봇들에게 접근에 대한 요청을 작성한 파일이다.
예컨대, 아래와 같은 파일이 작성되어있다고 해보자.
[robots.txt]
User-agent: *
Disallow: /
Sitemap: /sitemap
User-agent는 사용자를 대신해서 일을 수행하는 소프트웨어를 의미한다. 즉, 우리는 현재 보고 있는 페이지를 크롬이나 익스플로어와 같은 웹 브라우저 소프트웨어로 보고 있는 것이다.Disallow는 접근을 허용하지 않는 것을 명시하는 항목이다. 여기서는/(슬래시)로 표현 되어있는데, 현재 접속한 페이지를 포함한 내부 페이지들에 대한 로봇의 접근을 허용하지 않는다는 의미이다. 주로 비즈니스와 관련있거나, 중요한 정보를 담은 페이지는 이 항목으로 설정한다.- 예를 들어, 네이버에
https://naver.com는 사실 주소의 맨 끝에/가 생략이 되어있어서,https://naver.com/으로 표현할 수 있다. 맨 끝에 오는 슬래시 뒤로https://naver.com/blog/,https://naver.com/webtoon/과 같은 다양한 주소들이 붙게 되는데, 이러한 하위 페이지들에 대한 로봇의 접근을 전부 막는다는 의미이다. 그래서 네이버에서 만든 콘텐츠들은 다른 검색엔진(구글)에서 검색이 되지 않게 된다.
- 예를 들어, 네이버에
Allow: 로봇의 접근을 허용하는 항목이다.Sitemap: 웹 사이트의 구조를 한 눈에 보여주는 페이지이다. 전체 페이지에 대한 목록을xml형식으로 기계가 이해하기 쉬운 형태로 보여주는 것이다.

페이지 랭크(Page Rank)
페이지 랭크는 검색엔진에서 페이지마다 순위를 매기고, 사용자가 검색 했을 때 랭킹이 높은 사이트를 먼저 상위 노출 시켜주는 알고리즘을 의미한다.
.png)
예를 들어, 고양이에 대해 정보를 가지고 있는 A와 B사이트가 있다고 해보자. 나머지 C, D, E는 A사이트 링크를 표시한 페이지들이다. 이때, 다른 사이트와 링크가 많이 연결 되어있을수록 랭킹이 올라가게 된다. 그래서 검색 엔진에 고양이라고 검색했을 때, B보다 A가 상위에 노출된다.
그리고 A 사이트가 D 사이트를 향해 링크를 걸고 있으면, 다른 곳에서는 연결되어 있지 않은 사이트가 링크를 하는 것보다 훨씬 더 페이지랭크를 많이 올릴 수 있다.
이러한 특징 때문에 많은 스팸 사이트들이 페이지 노출을 위해 다양한 페이지에 링크를 남기는 방법을 사용하고 있다. 사람들을 낚기 위한 링크가 많이 퍼져 있을수록 사이트에 대한 페이지랭크가 올라가므로 사람들의 유입이 많아지게 된다. 이는 곧 더욱 큰 비즈니스 기회로 이어질 수 있다는 것이다.