개요
List에서 배열(Array)로 변환할 때 사용하는 메서드인 toArray()의 매개변수로 빈 배열을 넘기는 이유에 대해 정리했습니다.
List에서 Array로 변환하기
아래와 같이 List가 있다고 가정하겠습니다.
1
2
3
List<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
1. List 길이를 구한 다음 배열 생성
가장 간단한 방법은 List의 길이를 구한 다음 이에 맞는 크기의 String 배열을 생성해서 모든 원소를 하나씩 순회해서 복사하는 것입니다.
1
2
3
4
5
6
7
8
String[] arr = new String[list.size()];
for (int idx = 0; idx < list.size(); idx++) {
arr[idx] = list.get(idx);
}
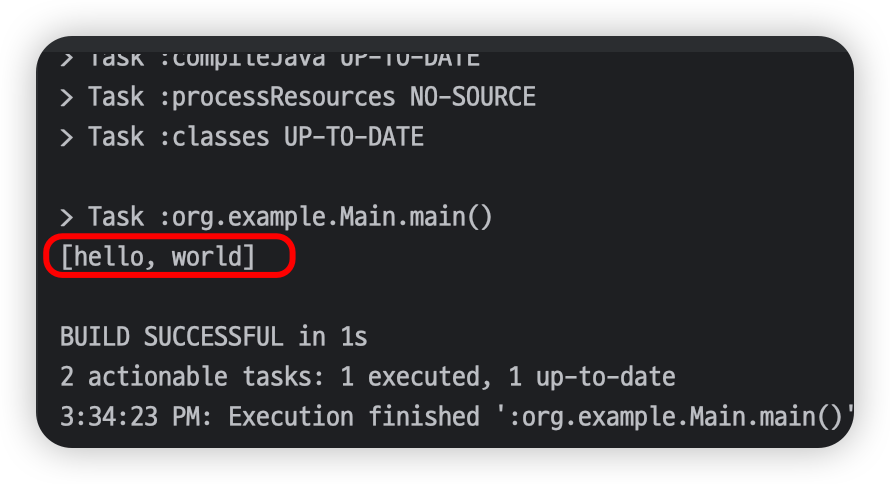
System.out.println(Arrays.toString(arr));
// [hello, world]
하지만 이 방법은 매번 반복문을 작성해야 하는 번거로움이 있습니다. 코드를 줄이고 효율적으로 배열을 생성하는 방법은 없을까요?
2. toArray() 메서드 사용
List 인터페이스에는 List를 배열로 변환하도록 돕는 toArray() 메서드가 존재합니다.
1
2
3
4
String[] arr = list.toArray(new String[0]);
System.out.println(Arrays.toString(arr));
// [hello, world]
단 1줄만으로 List를 배열로 변환했습니다. 인터페이스에 정의된 내용을 조금 더 자세히 살펴보면 다음과 같습니다.
1
2
3
// List.java
<T> T[] toArray(T[] a);
매개변수로 제네릭 타입의 배열을 받고 있는데, 위의 코드에서는 왜 new String[0] 을 전달했을까요?
왜 빈 배열을 전달해야 할까?
이를 이해하기 위해 구현체인 ArrayList를 살펴보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// ArrayList.java
public <T> T[] toArray(T[] a) {
// 1. 매개변수 배열 크기 < List 원소 개수
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
// 2. 매개변수 배열 크기 >= List 원소 개수
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
위의 코드에서 size는 ArrayList 클래스의 멤버 변수로, List에 저장된 원소 개수를 의미합니다. toArray(T[] a) 메서드는 아래와 같이 작동합니다.
| Case | Return |
|---|---|
| 1. 매개변수 배열 크기 < List 원소 개수 | List 길이에 해당하는 새로운 배열 생성 |
| 2. 매개변수 배열 크기 ≥ List 원소 개수 | 매개변수 배열에 List 원소들 복사 |
그렇다면 매개변수로 넘기는 배열의 크기를 위의 1번 방법처럼 List의 길이에 맞게 설정해서 전달해도 되는 것 아닌가라는 의문이 생깁니다.
1
String[] arr = list.toArray(new String[list.size()]);
위와 같이 작성하면 IntelliJ에서는 빈 배열을 전달할 것을 제안합니다.
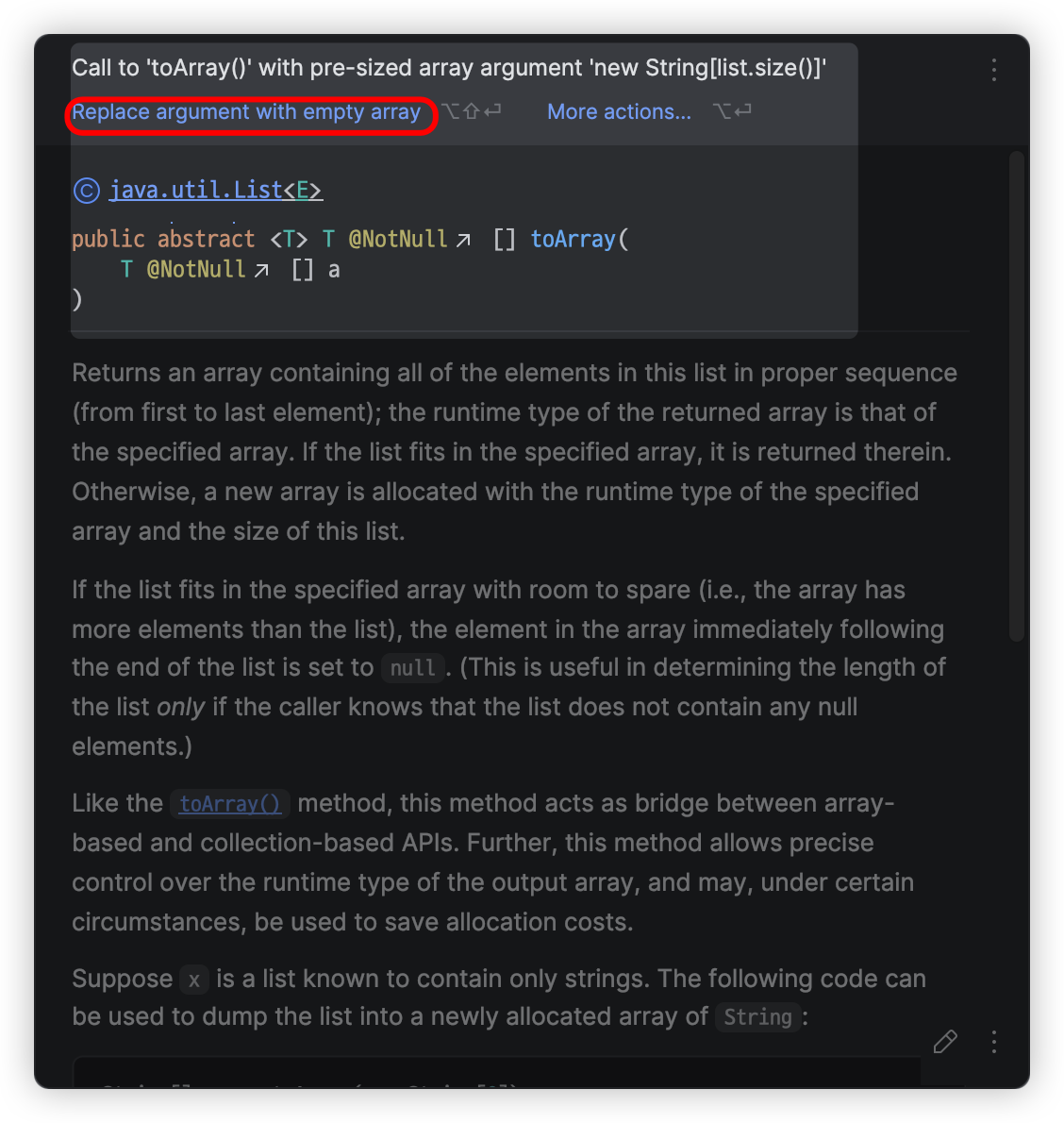
왜 IDE에서도 빈 배열을 넘길 것을 제안하는 걸까요? 그 이유는 멀티 스레드 환경에서 toArray() 메서드를 실행했을 때 오류가 발생할 수 있기 때문입니다.
빈 배열을 넘기는 이유에는 성능이 더 좋기 때문도 있지만, 이 글에서는 멀티 스레드 환경에서 왜 오류가 발생하는지 초점을 두고 설명하겠습니다.
Java는 여러 스레드가 같은 변수에 접근할 때, 연산 결과의 정합성이 보장될 수 있도록 메서드 선언부에 synchronized 키워드를 사용할 수 있게 지원합니다. 예시로 StringBuffer의 메서드들은 synchronized 키워드를 사용해서 선언되어 스레드 세이프 환경을 보장합니다.
1
2
3
4
5
6
// StringBuffer.java
@Override
public synchronized int compareTo(StringBuffer another) {
return super.compareTo(another);
}
하지만 ArrayList의 메서드 toArray()는 해당 키워드가 존재하지 않기 때문에 멀티 스레드 환경에서 연산 결과의 정합성을 보장하지 못합니다. 만약 멀티 스레드 환경에서 List 원소 길이가 10이고, 매개변수로 전달된 배열의 크기도 10이었다고 가정해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
// ArrayList.java
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
우선, List의 원소들을 배열에 복사하는 아래의 코드를 실행할 것입니다.
1
System.arraycopy(elementData, 0, a, 0, size);
배열에는 List의 모든 원소들이 복사되었습니다. 하지만 이 코드가 실행되고 나서 바로 다른 스레드에 의해 List의 원소를 삭제한 상황이 발생했다고 가정하겠습니다. 그렇다면 아래의 if문이 true가 되어 배열의 마지막 원소가 null로 저장됩니다.
1
2
if (a.length > size)
a[size] = null;
만약 다른 스레드에서 List의 원소를 삭제하지 않았다면, 위의 if문은 false가 되고, 배열의 마지막 원소는 null이 아닌 List의 마지막 원소가 저장됩니다.
이처럼 멀티 스레드 환경에서는 배열에는 저장되지 않아야 할 null 값이 저장되는 상황이 발생할 수 있습니다. 이를 표로 정리하면 아래와 같습니다.
| 상황 | 배열 원소 |
|---|---|
| 다른 스레드의 간섭 없음 | [hello, world] |
| 다른 스레드에 의해 List 원소 1개 삭제 | [hello, null] |
따라서 매개변수로 빈 배열을 넘기면, 배열의 마지막 원소가 null 처리가 되는 if문을 타지 않고 List 길이와 동일한 크기의 배열을 생성하기 때문에 마지막 원소에 null이 저장되는 문제가 발생하지 않습니다.
1
2
3
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
물론 빈 배열로 넘긴다고 해서 완벽하게 동시성 문제를 처리할 수 있는 것은 아닙니다. 이를 해결하기 위해 SynchronizedList나 CopyOnWriteArrayList를 사용할 수 있습니다.
빈 배열을 넘기지 않았을 때 마지막 원소가 null이 되는 예제 코드
멀티 스레드 환경에서 toArray() 메서드의 매개변수로 빈 배열을 넘기지 않았을 때, 반환된 배열의 마지막 원소가 null이 되는지 확인하는 예제 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
package org.example;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class Main extends Thread {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
Thread deleteThread = new Thread(() -> {
try {
Thread.sleep(1000);
list.remove(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread convertThread = new Thread(() -> {
try {
Thread.sleep(999);
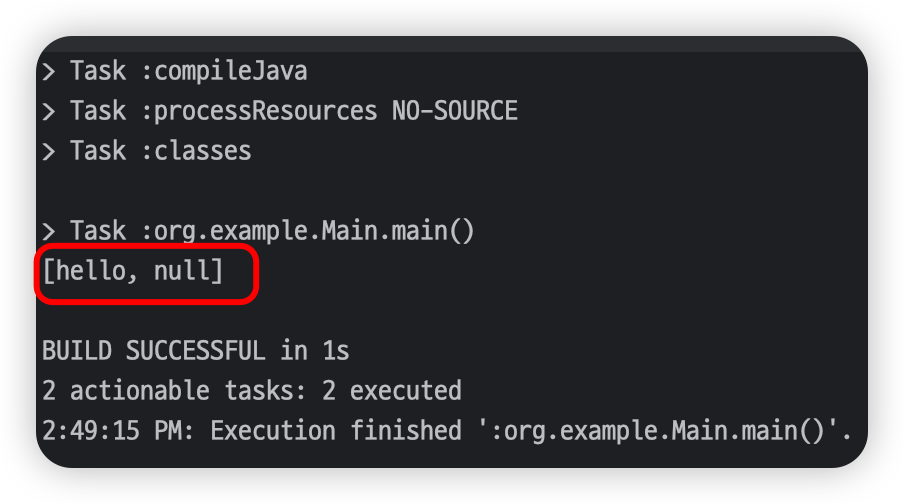
String[] arr = list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(arr));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
deleteThread.start();
convertThread.start();
}
}
List의 원소를 삭제하는 deleteThread와 toArray() 메서드를 사용해서 배열로 변환하는 convertThread를 생성했습니다. convertThread가 먼저 실행되고 deleteThread가 실행되도록 스레드 실행 순서와 스레드 내의 sleep 시간을 조정했습니다.
실행할 때마다 매번 null이 마지막 원소로 들어가는 것은 아니지만, 멀티 스레드 환경에서 toArray() 메서드를 사용하면 의도하지 않은 결과가 나타날 수 있습니다.
이러한 동시성 문제를 해결하기 위해 synchronizedList와 synchronized 키워드를 사용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
package org.example;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = Collections.synchronizedList(new ArrayList<>());
list.add("hello");
list.add("world");
Thread deleteThread = new Thread(() -> {
try {
Thread.sleep(1000);
list.remove(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread convertThread = new Thread(() -> {
try {
Thread.sleep(999);
String[] arr;
synchronized (list) {
arr = list.toArray(new String[list.size()]);
}
System.out.println(Arrays.toString(arr));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
deleteThread.start();
convertThread.start();
}
}
코드를 여러 번 실행해도 List에서 배열로 변환하는 시점에는 List의 마지막 원소가 삭제되지 않은 상태가 보장되기 때문에 배열의 원소가 항상 2개로 출력되는 것을 확인할 수 있습니다.