
GET과 POST 방식
웹 개발을 하면 <form> 태그의 속성으로 method를 설정해주어야 하는데, 크게 GET 방식과 POST 방식으로 나뉜다. 간단하고 쉽게 요약을 하자면, GET 방식은 서버에서 정보를 조회할 때 주로 쓰이고, POST 방식은 정보를 수정하거나 입력할 때 사용한다. 자세하게 이를 이해하기 위해서는 HTTP에 대한 이해가 필요하다. 본 문서에서는 네트워크에 대해 자세히 다루지는 않지만, 전반적인 내용을 담기 위해 노력했다.
HTTP(HyperText Transfer Protocol)
HTTP는 웹 클라이언트가 웹 서버에 어떻게 요청하고, 반대로 웹 서버는 어떻게 웹 클라이언트에게 전송하는 지를 정의하고 있는 프로토콜(규약, 약속)이다.
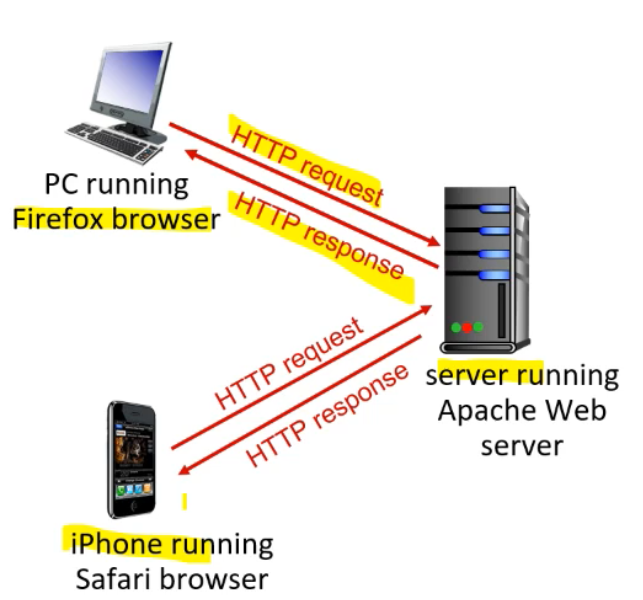
HTTP는 클라이언트/서버 모델로 구성되어있다.
- 클라이언트 : 브라우저에서 원하는 HTTP 객체를 웹 서버에 요청(request)하고, 이를 수신해서 화면에 띄운다.
- 서버 : 브라우저가 요청한 객체에 대해서 HTTP 프로토콜을 사용해서 응답(response)한다.
HTTP Request Message
클라이언트와 서버가 서로 정보를 요청하는 데 사용하는 메세지이다.
Request message는 크게 4가지 부분으로 나뉜다.
- Request Line(요청 라인)
- 데이터 처리 방식(HTTP Method)와 기본 페이지, 프로토콜 버전이 포함된다.
- Request Header(요청 헤더)
- User-Agent, Accept, Cookie, Referer, Host 정보가 포함된다.
- User-Agent : 사용자 웹 브라우저 종류 및 버전 정보가 포함된다. Ex)
Chrome/51.0.2704.103: 크롬 브라우저 51.0.~버전 사용자임을 알 수 있다. - Accept : 웹 서버로부터 수신되는 데이터 중 웹 브라우저가 처리할 수 있는 데이터 타입을 의미 Ex)
text/html: text, html 형태의 문서를 처리할 수 있고,*/*는 모든 문서를 처리할 수 있다는 의미(MIME 타입) - Cookie : HTTP 프로토콜은 클라이언트에 대해 어떠한 정보도 유지하지 않는
Stateless방식(세션 유지X) 이기 때문에 로그인 인증에 있어 사용자 정보를 기억하려고 만든 인위적인 값이다. - Referer : 현재 페이지 접속 전에 어느 사이트를 경유했는지 알려주는 도메인 또는 URL 정보가 포함된다.
- Host : 사용자가 요청한 도메인 정보 포함
- User-Agent : 사용자 웹 브라우저 종류 및 버전 정보가 포함된다. Ex)
- User-Agent, Accept, Cookie, Referer, Host 정보가 포함된다.
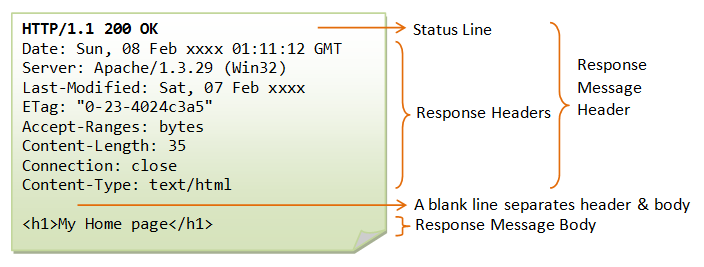
- A blank line separates header & body(공백 라인)
- 헤더와 본문을 구분하기 위한 캐리지 리턴(
\r)과 라인 피드(\n)으로 구성되어 있다. - 캐리지 리턴은 커서를 맨 앞으로 이동시키고, 라인 피드는 커서를 한 줄 아래로 이동시키는 것이다.
- 즉,
\r \n은 키보드의Enter와 동일한 기능을 한다고 생각하면 된다.
- 헤더와 본문을 구분하기 위한 캐리지 리턴(
Request Message Body(메세지 본문)
- 요청과 관련된 정보가 담겨있다. HTTP 메세지의 실질적인 내용이 포함된 페이로드(payload)는 바디(body)라고 부른다.
이름 명칭 Request Line Header(헤더) Request Header Request Message Body Body(바디)
Request Line에 HTTP Method에 대한 정보가 패킷에 실리는데, 아래와 같이 다양한 Method가 존재한다. 그 중에서도 CRUD(Create, Read, Update, Delete)에 사용되는 메소드 4가지만 소개하자면 다음과 같다.
| Request Method | 기능 |
|---|---|
| GET | 서버에게 Resource(자원)을 보내도록 요청. 데이터를 수신하는 기능. |
| POST | 서버에 Input Data를 전송. |
| PUT | 서버의 Resource에 데이터를 저장하기 위해 사용(GET과 반대) |
| DELETE | 서버에게 Resource를 삭제하도록 요청. HTTP 규격에는 클라이언트가 DELETE 요청을 보내도 무효할 수 있도록 정의되어 있다. 따라서 항상 보장되지는 않는다. |
이 문서에서는 GET과 POST에 대해서만 설명하고자 한다.
GET 방식
GET은 서버로부터 정보를 조회하기 위해 설계된 메소드이다.
[특징]
- URL에 변수(데이터)를 포함시켜 요청한다.
- 데이터를 Header(헤더)에 포함하여 전송한다.
- URL에 데이터가 노출되어 보안에 취약하다.
- 캐싱이 가능하다.
GET은 요청을 전송할 때, 필요한 데이터를 Body가 아닌 쿼리스트링을 통해 전송한다. URL의 끝에 ?와 이름과 값으로 쌍으로 이루는 요청 파라미터를 쿼리스트링이라고 한다. 만약, 요청 파라미터가 여러 개일 경우, &으로 연결한다. 쿼리스트링을 사용하면 URL에 조회 조건을 표시하기 때문에 특정 페이지를 링크하거나 북마크(즐겨찾기) 할 수 있다.
쿼리스트링을 포함한 URL은 다음과 같다. 요청 파라미터는 id, pw이고, joon, 1234 값으로 서버로 요청을 보내게 된다.
http://localhost/sign_up
?id=joon&pw=1234...
그리고 GET은 불필요한 요청을 제한하기 위해 요청이 캐시될 수 있다. css, js, 이미지와 같은 정적 콘텐츠는 데이터가 크고, 변경될 일이 적기 때문에 반복해서 동일한 요청을 보낼 필요가 없기 떄문이다. 정적 콘텐츠를 요청하면 브라우저는 요청을 캐시해두고, 동일한 요청이 발생하면 서버로 요청을 보내지 않고 캐시된 데이터를 사용한다.
그래서 프론트엔드 개발을 하다보면 정적 콘텐츠를 변경해도 내용이 바뀌지 않는 경우가 발생한다. 이는 브라우저에 저장된 캐시가 변경되지 않았기 때문인데, 브라우저의 캐시를 지워주면 다시 콘텐츠를 조회하기 위해 서버로 요청을 보내고, 변경한 내용이 반영된 것을 확인할 수 있다.
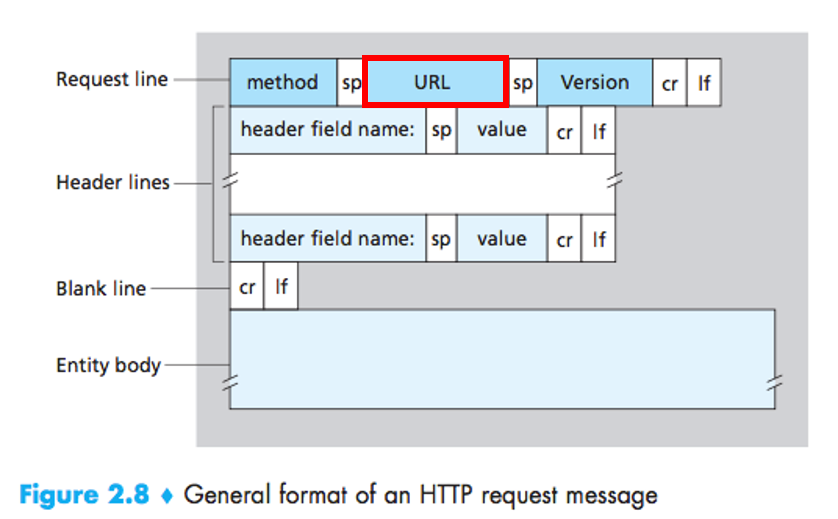
위의 사진은 HTTP request message의 패킷 구조이다. 사진에 표시된 URL부분에 Input Data가 실려서 서버로 보내지는 것이다.
하지만, GET방식은 중요 정보가 URL에 모두 노출되기 때문에 보안에 취약하다는 단점이 존재한다.
참고로 과거에는 장비 성능의 한계로 URL 길이를 256자로 제한하고는 했으나, http1.1 이후로는 무제한의 URL을 지원한다고 한다. 다만, 브라우저에 따라 최대 길이를 제한하기도 하며, 너무 길어지는 경우 초과 데이터는 절단된다고 한다.
POST 방식
POST는 서버에 저장된 리소스를 생성 및 변경하기 위해 설계된 메소드이다. GET과 달리 전송할 데이터를 HTTP 메세지의 Body에 담아서 전송한다.
특징
- URL에 변수(데이터)를 노출하지 않고 요청한다.
- 데이터를 Body(바디)에 포함시킨다.
- URL에 데이터가 노출되지 않기에 기본적인 보안은 보장된다.
- 캐싱이 불가능하다.
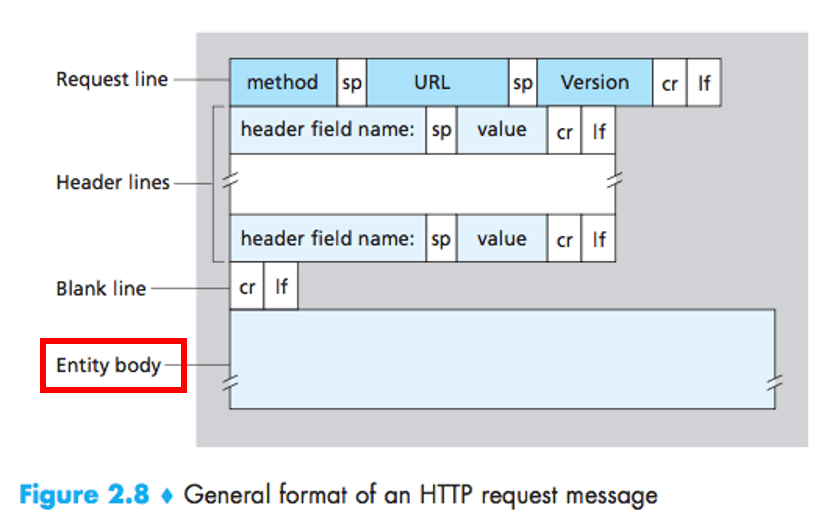
Body에 데이터를 넣어서 전송하기 때문에 헤더필드에서 데이터에 대한 설명을 담은 Content-Type 헤더 필드가 들어가고, 어떤 데이터 타입인지 명시해주어야 한다.
데이터를 Body에 포함시키기 때문에 메세지 길이에 제한은 없지만, 요청 시간이 과도하게 길어진다면 응답을 받는 시간도 비례해서 길어지는 문제를 방지하기 위해 Time Out이 존재한다. 그래서 클라이언트에서 페이지를 요청하면 기다리는 시간이 존재하게 된다.
하지만, 데이터가 Body에 전송된다고 해서 보안에 안심할 수 있는 것은 아니다. 크롬 개발자 도구나 Wireshark와 같은 패킷 분석 도구를 이용한다면 충분히 Body의 내용을 확인할 수 있다. 따라서 보안에 민감한 데이터를 주고 받는 경우에는 반드시 암호화해서 전송하는 것이 필요하다.
GET과 POST 비교
GET은 Idempotent, POST는 Non-idempotent하게 설계 되었다. Idempotent(멱등)은 수학적 개념인데, 다음과 같이 설명할 수 있다.
수학이나 전산학에서 연산의 한 성질을 나타내는 것으로, 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질.
즉, 멱등은 동일한 연산을 여러 번 수행해도 동일한 결과가 나타나야 한다는 것이다.
GET이 Idempotent하도록 설계되었다는 것은 GET으로 서버에 동일한 요청을 여러 번 전송해도, 동일한 응답이 돌아온다는 것을 의미한다. 그래서 GET은 서버의 데이터나 상태를 변경시키지 않아야 하기 때문에, 주로 데이터를 조회할 때 사용해야 한다. 예를 들어, 브라우저에서 웹 페이지를 열거나, 게시글을 읽는 등 조회를 하는 행위는 GET으로 요청한다.
반면 POST는 Non-idempotent하기 때문에, 서버에 동일한 요청을 여러 번 전송해도 각기 다른 응답을 받을 수 있다. 그래서 POST는 서버의 상태나 데이터를 변경시킬 때 사용된다. 예컨대, 게시글을 쓰면 서버에 게시글이 저장되고, 게시글을 삭제하면 해당 데이터가 삭제되는 등 서버에 변화를 일으키는데 사용된다. 이처럼 POST는 생성, 수정, 삭제에 사용할 수 있지만, 생성에는 POST, 수정은 PUT, 삭제는 DELETE가 용도에 맞는 메소드라고 할 수 있다.
| 처리 방식 | GET | POST |
|---|---|---|
| URL 데이터 노출 여부 | O | X |
| URL 예시 | http://localhost:8080/sign_up?id=joon&pw=1234 | http://localhost:8080/sign_up |
| 데이터의 위치 | Header(헤더) | Body(바디) |
| 캐싱 가능 여부 | O | X |
| 요청 결과 | 동일(Idempotent) | 변동가능(Non-idempotent) |
앞에서 살펴본 것 처럼 GET과 POST는 큰 차이가 있으므로, 설계 원칙에 따라서 적절하게 사용되어야 한다.
참고자료
- https://mangkyu.tistory.com/17
- https://hongsii.github.io/2017/08/02/what-is-the-difference-get-and-post/
- https://khj93.tistory.com/entry/GET-%EB%B0%A9%EC%8B%9D%EA%B3%BC-POST-%EB%B0%A9%EC%8B%9D-%EC%9D%B4%EB%9E%80-%EC%B0%A8%EC%9D%B4%EC%A0%90